By barneyb on November 10, 2011
Before you click over this because you know me as a Flash hater, give me two seconds. That's not what this post is about. It's about a larger issue. It's about how awesome it is to be a web developer these days.
Ten years ago, being a web developer sucked. Deployment was easy (rsync to production [...]
Posted in ajax, development, flex, javascript, tools
By barneyb on May 17, 2011
In the handful of months since I last posted about inline progress bars, I've made some enhancements to the mechanism. In particular, the original mechanism didn't handle overages very gracefully, and while overage isn't strictly needed for progress, I've ended up wanting the same inline display for other types of measurements (e.g., fundraising dollars against [...]
Posted in css, development, javascript
By barneyb on February 20, 2011
If you develop web apps for Android devices, there's a really gnarly bug you should be aware of: setTimeout and setInterval will never fire while the soft keyboard is open. When the soft keyboard closes, all the queued up timeouts/intervals will unspool all at once, which is not terribly good, but better than them disappearing. [...]
Posted in javascript
By barneyb on September 15, 2010
2011-05-17: A richer version is available at http://www.barneyb.com/barneyblog/2011/05/17/even-better-inline-progress-bars/.
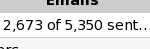
If you've ever built a web app that does background and/or batch processing of stuff, you've invariably created a bit of markup like this:
#numberFormat(sentEmailCount, ',')# of #numberFormat(emailCount, ',')# sent…
which then renders like this:
Wouldn't it be nice to create this markup (simply with a wrapping span) instead:
#numberFormat(sentEmailCount, ',')# of [...]
Posted in javascript
By barneyb on August 3, 2010
A couple years ago I wrote about using YUI Compressor to do built-time aggregation and compression of static assets. That works well and good if you have a build environment, but that's not always the case. So, still using YUI Compressor, I set up a simple script that'll do runtime aggregation and compression of assets [...]
Posted in cfml, javascript, tools
By barneyb on January 15, 2010
For quite some time now I've had a sidebar widget that displays an excerpt of my Twitter feed on my blog. It uses the standard Twitter JSON/P interface for loading the tweets and then a Twitter-provided script (http://twitter.com/javascripts/blogger.js) for rendering them on the page. Unfortunately the default installation instructions would have you set up something [...]
Posted in javascript, meta
By barneyb on June 3, 2009
Last night I needed a simple HTML table with sortable columns, and after a quick Googling, found the TableSorter jQuery plugin. I'd come across it before, but never actually used it. Added a class to my table (for targeting and to leverage the CSS that it comes with), added the required line of JavaScript to [...]
Posted in javascript
By barneyb on April 10, 2009
If you only ever use the type-specific event helpers (.click(), .load(), .change(), etc.), you're potentially missing out on a really handy feature of jQuery: bind data. Bind data is data associated with the bound handler function, available to every invocation of it, but not in any "normal" variable scope. It's kind of like currying, except [...]
Posted in javascript
By barneyb on April 9, 2009
If you're using the new jQuery.live("type", fn) handlers in jQuery 1.3, be careful with the "click" event type. Unlike jQuery.bind("click", fn) and jQuery.click(fn), jQuery.live("click", fn) doesn't distinguish between mouse buttons. So while the "normal" handlers will only trigger when the left button is used, the live handler will trigger on any button.
The workaround is pretty [...]
Posted in javascript
By barneyb on March 17, 2009
Ray Camden posted an interesting article over on InsideRIA about expanding short urls using jQuery and ColdFusion. After reading the article, I thought he was overcomplicating things somewhat by relying on the url shortening services' APIs to do the lookups. Yes, that's what APIs are for, but for this case, HTTP happens to be a [...]
Posted in cfml, development, javascript